
 There’s a saying, often mis-attributed by Americans to Mark Twain, who equally mis-attributed it to Disraeli, who may well have been using a similar phrase common at the time (the 1880-1890s)[1]. It goes; “There’s lies, damned lies, and statistics.”
There’s a saying, often mis-attributed by Americans to Mark Twain, who equally mis-attributed it to Disraeli, who may well have been using a similar phrase common at the time (the 1880-1890s)[1]. It goes; “There’s lies, damned lies, and statistics.”
Nowhere does this appear more rife than the internet where figures are bandied around with little consideration for their logic, sources, or real meaning. Statistics are having a massive resurgence in importance these days. We need to make sense of all this “big data” which the controlling elements in the Government seem to love [3], newspapers seem to fear, and which Google, Amazon, eBay, TripAdvisor and all the ‘social media’ platforms, make their money from. ‘We’ is perhaps not quite right – it’s really that we benefit from the hard working algorithms (which are almost always statistically-bound) that these firms have invested heavily in.
Access to such powerful datasets, as much as the power of the systems used to analyse them, has led to a growth in ever more complex processing of data – again, statistically-bound. Anyone familiar with the most popular TED talks will have seen the extraordinary graphical representations of these number-crunching (or, more often, number filtering) exercises demonstrated by Hans Rosling [2]. I just love the bio note for him on their site – a data visionary in whose hands data sings!

Areas of statistics untapped for decades (and even centuries in some cases, I suspect, as many were devised by Indian and Arabic mathematicians that long ago) are finding new meaning in the world of Web 3.0. Their ability to predict a future out of a myriad of events today forms the bedrock of this brave new world. This week, Google launched their “Material Design“. It is a whole new way of looking at software engineering, user-interfacing, and the operating systems behind them. It will, they confidently expect, provide much needed stimulus to this highly interactive new era.
Imagine, leaving work, taking a few steps in the direction of the ‘tube’ (aka ‘Metro’) and as you walk your phone is constantly predicting where you might end up? Looking backwards is easy – we have that already… If you browsed Indian restaurants in South Kensington earlier that day then it isn’t rocket science for the phone to infer that you might be heading there now. Looking forwards is much more statistically-bound. As you enter the tube, the phone senses that you are following your usual path home. It detects your pace and predicts which train you’ll catch and when you’ll arrive in Worplesdon or wherever home is. It checks the contents of your fridge and determines that you’ve got a half empty jar of now fungally-encroached Laksmi paste, and an unopened one of Pesto. It has already determined that your partner left work half an hour earlier than usual and has headed in the opposite direction, meeting three friends in a pleasant restaurant in Soho. It vibrates quietly in your pocket. You pull it out, and it springs to life recognising your face as its true owner. The simple, clear interface, shows you recommended pasta dishes, a suggested menu of programmes to watch on iPlayer, and the names of a couple of friends who are home-alone too and with whom you often have a pint at the local… You decide to do just that, touch their image and the phone rings them…
This is not the stuff of science fiction – it is only a couple of years away – in practice, there are probably a few folks already doing it. And it is dependent on predictive reasoning enabled by statistics.
All great stuff. Of course, some systems are just not as sophisticated. One area that you might expect to be very clever, and yet seems fraught with problems is that of online reputation management. I don’t mean the problems of revenge porn either. Social media engines depend, for their income, on raising the profile of their subscribers. They generate rankings, placing the members according to the number of times they use the platform, the number of friends that they have and how many of those share their messages and so on. The algorithms are complex and the statistics behind them are sophisticated. Companies, promoting brands in this way, pay a fortune to have their profile raised and so enhance their reputation. There are also meta-ranking systems that pool these stats and produce composites. One of these is Naymz. It gathers your data and provides a regular report of how popular you are. However, sometimes, the statistics don’t quite match up to human interpretation.
For example, here’s a report from Naymz showing how my own profile is fairing;
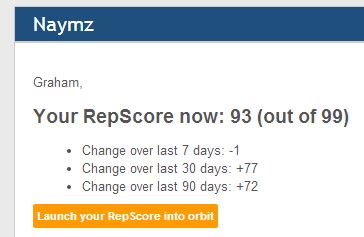
You might notice a slight discrepancy there…
All of which goes to suggest that you should lay in increasing stocks of salt from which to take pinches every time you read some awesome fact that you never knew!
Best wishes
Graham
[2]
[3] In an analysis of the misuse of statistics (primarily to mislead the public) the Department for Works and Pensions apparently reigns supreme – according to recently released government statistics that is!



